Creación de datasets
Dentro de la sección de datasets se pueden crear tantos dataset como se desee. Para crear un nuevo dataset solo hay que que poner el punterio del ratón sobre en el botón que se encuentra en la parte inferior derecha de la pantalla en la sección de datasets, y hacer clic la opción de dataset. Aparece el siguiente diálogo de creación de dataset.
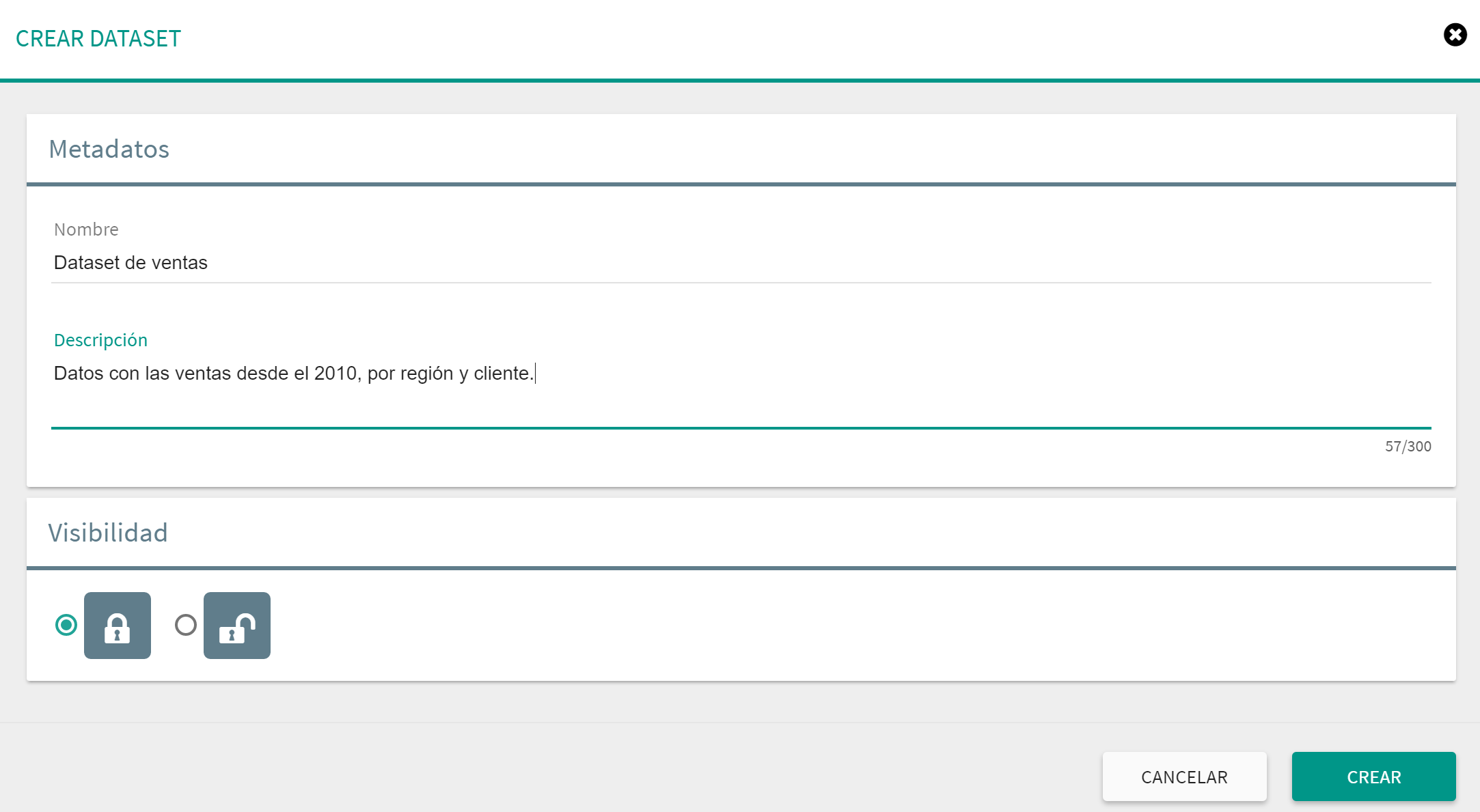
Este diálogo incluye la información esencial de un dataset: nombre, descripción y si se trata de un dataset público o privado. En el caso de seleccionar la opción de dataset público todos los usuarios de Tabulae podrán ver el contenido de ese dataset. Por otro lado, si se selecciona la opción de privado, solamente el usuario que creo el dataset tendrá acceso al mismo.
Una ver creado el dataset se podrán incluir datos utilizando una de las opciones que se muestra a continuación:
| Icono | Tipo de fuente |
|---|---|
|
|
Empezar desde cero (a mano) |
|
|
Carga desde fichero local |
|
|
Carga desde BBDD Sql |
|
|
Carga desde BBDD NoSql |
|
|
Carga desde Google Drive |
|
|
Carga desde Google Analytics |
|
|
A partir de otro dataset |
Desde cero
Esta es la opción más sencilla para crear un dataset. Tabulae creará un dataset vacío de 5 columnas por 5 filas. Una vez creado se podrán añadir tantas filas y columnas como sea necesario y modificar el contenido de las celdas usando el editor.
Desde fichero (CSV, Excel)
Esta opción permite crear un dataset a partir de:
Una vez seleccionada esta opción se abrirá el diálogo de selección de fichero del navegador y comenzará el wizard de importación de datos en función del formato del fichero importado.
Warning El tamaño máximo de fichero que se puede subir por defecto es de 5 Mb. No obstante este límite es variable en función de las necesidades del usuario (contactar con el administrador de Tabulae).
Importar un CSV
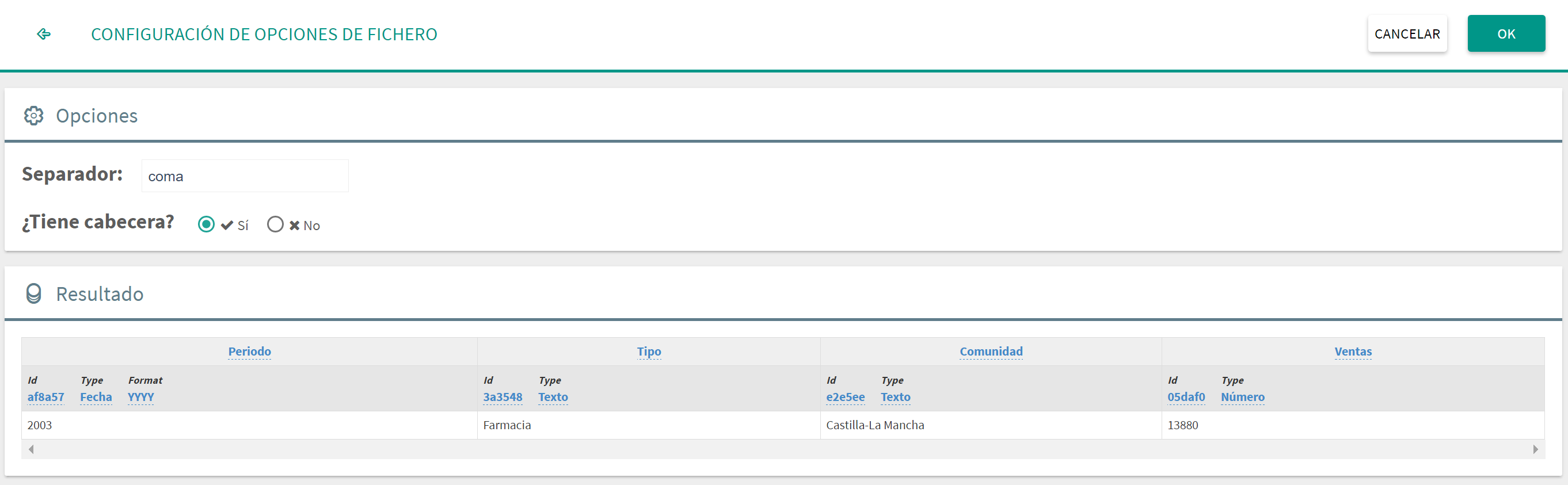
El fichero importado ha de tener obligatoriamente una extensión .csv. En el diálogo de importación aparecen las siguientes opciones:
Separador: Permite indicar el carácter de separación usado en el fichero. Se pueden seleccionar entre: coma, punto y coma, barra, tabulador y espacio.
¿Tiene cabecera? Es decir, si el fichero incluye en la primera línea el nombre de las columnas.
Resultado: En esta parte se ve la primera fila que se subirá al dataset a modo de ejemplo. A partir de ella se puede visualizar si la identificación autómatica es correcta, y además se permite cambiar los nombres de las columnas, los tipos de datos y los identificadores internos de Tabulae. Para realizar cualquiera de estas modificaciones solo hay que hacer clic encima de la propiedad que se quiere modificar, escribir el nuevo valor y pulsar Enter.
Warning Se recomienda dejar los identificadores que genera Tabulae, y en caso contrario usar códigos cortos para facilitar el funcionamiento interno de la herramienta. Se permite usar identificadores repetidos, pero el usuario debe saber en que casos así ocurre para evitar posteriores errores al invocar esos datasets desde una aplicación.
Importar un Excel

El fichero importado ha de tener obligatoriamente una extensión .xls o .xlsx. En el diálogo de importación aparecen las siguientes opciones:
¿Tiene cabecera? Es decir, si el fichero incluye en la primera línea el nombre de las columnas.
Número de hoja: Se indica la posición de la hoja que nutrirá el dataset (1 hoja por dataset!).
El proceso de lectura del fichero excel espera datos en forma tabular, es decir, dada una hoja se busca un origen de datos en una celda en la parte superior izquierda, y se leen las columnas a la derecha y filas hacia abajo que tengan datos. Cuando se llega a la parte inferior derecha donde ya deja de haber datos se para la lectura.
Warning Es responsabilidad del usuario que los datos a importar sean realmente tabulares para evitar cargar datos espurios (celdas que se han quedado informadas por error, multiples rangos tabulares en una misma hoja, etc.).
Los tipos de dato de las columnas serán seleccionados automáticamente teniendo en cuenta los tipos de celda de las columnas seleccionadas en el fichero excel.
Warning En caso de haber diferencias de tipos de celda a lo largo del rango tabular que se está leyendo puede haber errores o diferencias con los datos originales en el dataset de Tabulae.
Desde base de datos SQL
Si se selecciona la opción de crear un dataset desde una base de datos SQL se deberá cumplimentar la información que se incluye en el diálogo:
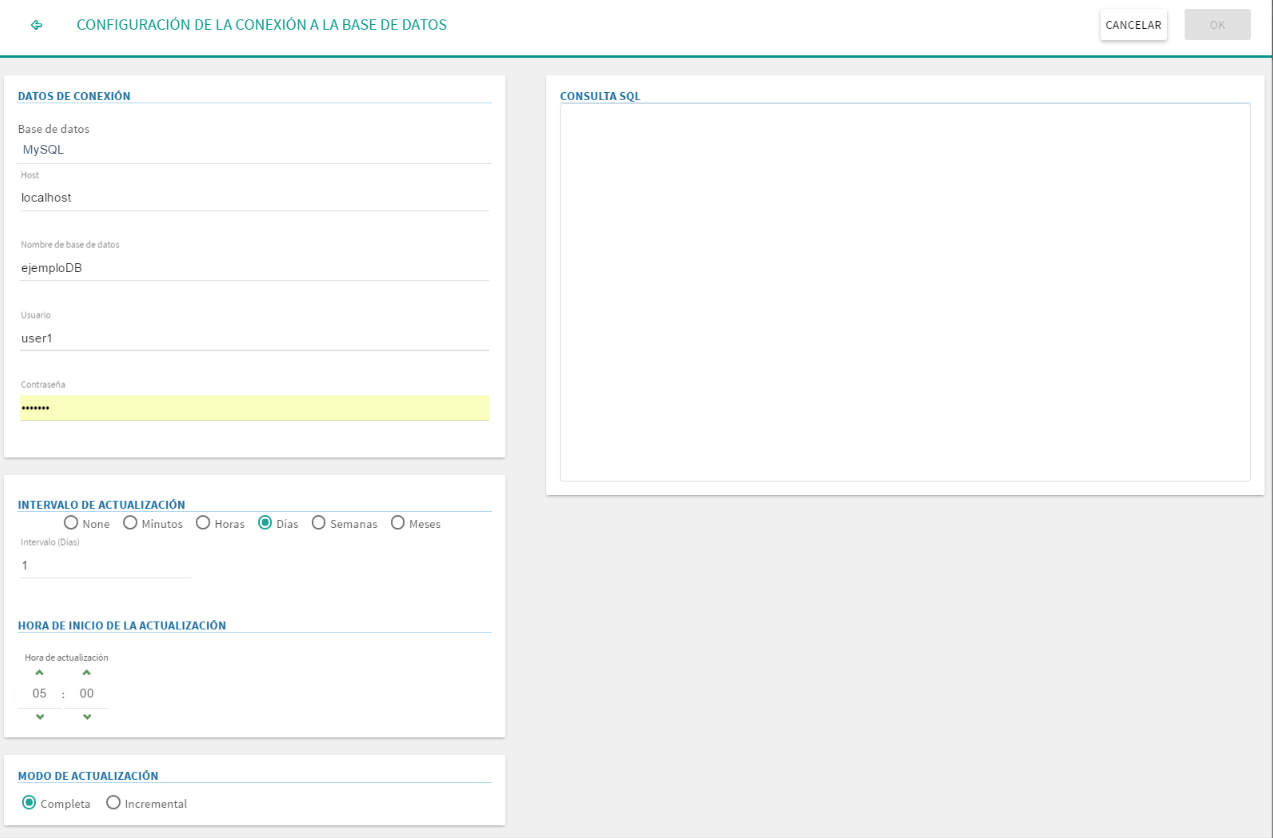
Tipo de base de datos: Tabulae puede leer por defecto información de MySQL, SQL Server, PostgreSQL y Oracle. En caso de necesidad se puede solicitar la inclusión de un nuevo gestor, o bien de un conector para versiones muy antiguas.
Host: Dirección IP donde se encuentra la base de datos. Si el puerto en el que escucha la base de datos no es el puerto por defecto se puede añadir a continuación del host separandolo por ":", por ejemplo
localhost:5433.Nombre de la base de datos
Usuario: Usuario con permisos de lectura en la base de datos.
Contraseña: Contraseña del usuario usado para la conexión.
Refresco: El dataset se puede actualizar automáticamente cada cierto intervalo de tiempo, eligiendo la cantidad de minutos, horas, días, semanas o meses, así como la hora de inicio de la ejecución (excepto para minutos u horas, donde se toma como referencia la hora de creación/actualización anterior del dataset). La actualización se encola, y depende además de la carga del servidor de origen y de destino, por lo que puede realizarse algunos minutos después de lo esperado.
Consulta SQL: Consulta SQL con la que se quiera recuperar los datos para la creación del dataset.
Tabulae permite además realizar dos tipos de atualización:
Completa: La actualización completa permite volcar todos los datos que devuelve la consulta SQL sustituyendo completamente el contenido del dataset.
Incremental: Si los datos de la base de datos relacional cumplen ciertos requisitos se podrá realizar una actualización incremental que moverá al dataset sólo una parte de los datos disponibles en la base de datos original. Este tipo de actualización es el recomendable cuando el volumen de datos a mover es elevado.
Para que se pueda realizar una actualización incremental la tabla o tablas usadas en la consulta deberán disponer de una columna que permita obtener sólo los datos añadidos desde la última actualización, como pueden ser un identificador incremental o una fecha.
A continuación se detallan los pasos a seguir para configurar una actualización incremental:
Seleccionar el modo "Incremental".
Aparece una nueva sección "Condición" que permite definir la condición que limita el número de registos devueltos por la consulta. Para ello habrá que cumplimentar los campos "Columna incremental" y "Variable".
Columna incremental: Es la columna de la base de datos que se utiliza como referencia para obtener únicamente los datos añadidos desde la última actualización. Generalmente se trata de una columna autoincremental o de una fecha.
Variable: Es la variable que utiliza internamente tabulae para almacenar el último valor obtenido desde la base de datos original. El valor por defecto es $last_value$ y generalmente no hay que modificarlo. Se permite editarlo únicamente por si hubiese que aplicar alguna función específica a dicho valor.
Añadir a la sentencia SQL una clausula "where $condition$". El sistema se encargará de sustituir la variable $condition$ por la condición adecuada en cada caso para obtener únicamente los datos que hayan sido añadidos desde la última sincronización.
Ejemplo de actualización incremental: si se tiene una tabla de ventas con una columna PK con la fecha de la venta se podría usar esa columna para incorporar a Tabulae únicamente las ventas realizadas desde la última sincronización.
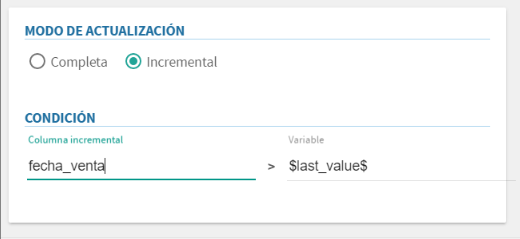
Imagen - Configuración de la condición para actualizaciones incrementales 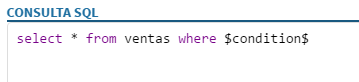
Imagen - Configuración de la consulta para actualizaciones incrementales
Desde base de datos NoSQL
Si se selecciona la opción de crear un dataset desde una base de datos NoSQL hay diferentes opciones, que en general no comparten el mismo estándar. En Tabulae se encuentran las siguientes opciones:
MongoDB (aggregation)
Se debe cumplimentar la información relativa a la conexión:
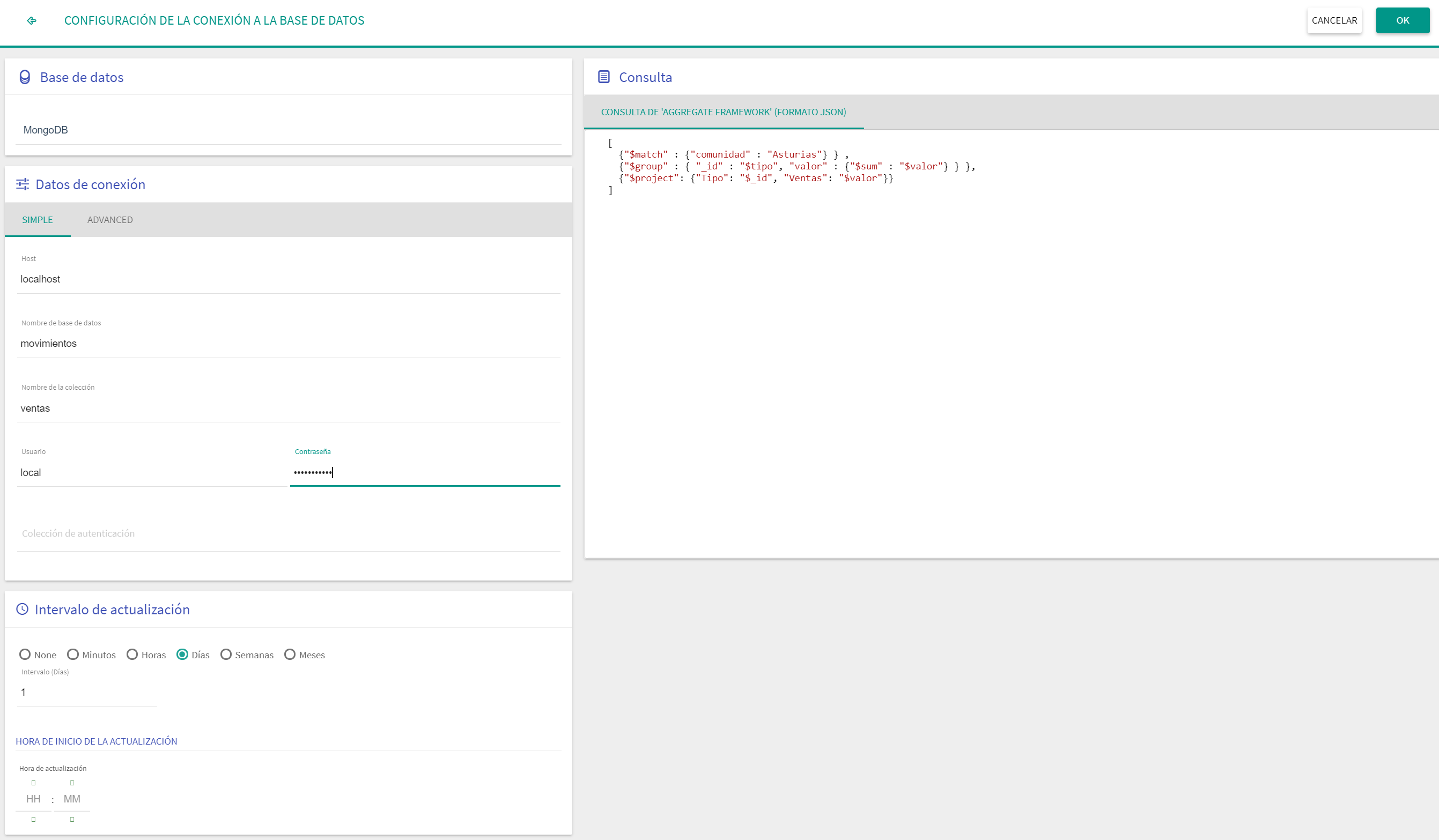
Conexión Simple: Es una conexión directa a un servidor normal.
Host: Dirección IP donde se encuentra la base de datos. Si el puerto en el que escucha la base de datos no es el puerto por defecto se puede añadir a continuación del host separandolo por ":", por ejemplo
localhost:27017.Nombre de la base de datos
Nombre de la colección de datos
Usuario: Usuario con permiso de lectura en la base de datos.
Contraseña
Colección de autenticación
Conexión Avanzada: Es una conexión en forma de cadena por ejemplo para BBDD clusterizadas.
URI de conexión: Cadena con los parámetros de conexión a la BBDD.
Nombre de la colección de datos
Intervalo de actualización: El dataset se puede actualizar automáticamente cada cierto intervalo de tiempo, eligiendo la cantidad de minutos, horas, días, semanas o meses, así como la hora de inicio de la ejecución (excepto para minutos u horas, donde se toma como referencia la hora de creación/actualización anterior del dataset).
Consulta: Consulta con la que se quiera recuperar los datos para la creación del dataset (asociada al tipo de base de datos elegida).
Warning En el caso de usar el aggregation framework de MongoDB la consulta debe ir en formato "json" válido: pares (campo, valor) con las comillas y estructura de llaves y corchetes correcta. Ejemplo de json válido:
[ {"$match" : {"comunidad" : "Asturias"} } , {"$group" : { "_id" : "$tipo", "valor" : {"$sum" : "$valor"} } }, {"$project": {"Tipo": "$_id", "Ventas": "$valor"}} ]
MongoDB MapReduce
Se debe cumplimentar la información relativa a la conexión:
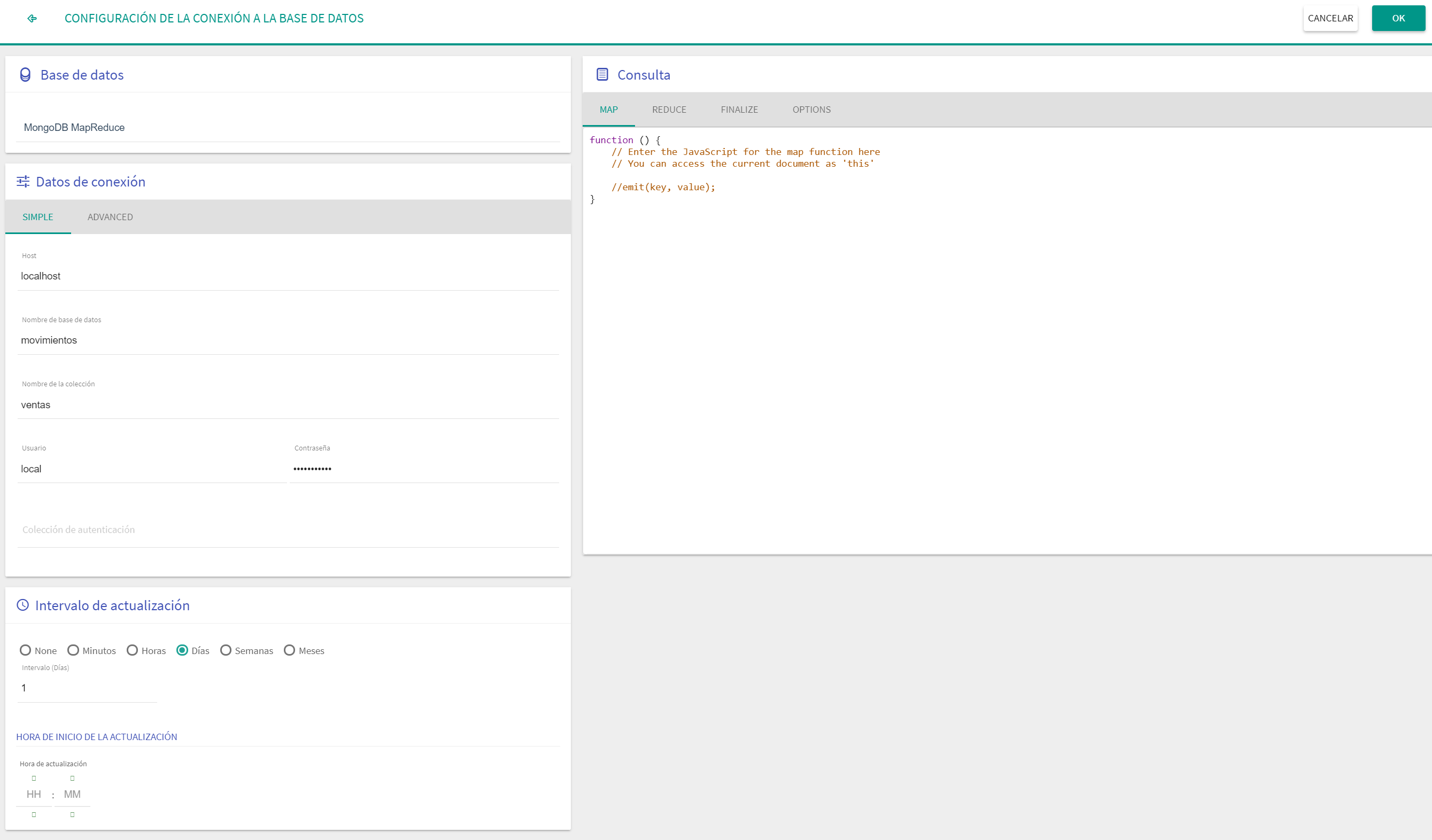
Conexión Simple: Es una conexión directa a un servidor normal.
Host: Dirección IP donde se encuentra la base de datos. Si el puerto en el que escucha la base de datos no es el puerto por defecto se puede añadir a continuación del host separandolo por ":", por ejemplo
localhost:27017.Nombre de la base de datos
Nombre de la colección de datos
Usuario: Usuario con permiso de lectura en la base de datos.
Contraseña
Colección de autenticación
Conexión Avanzada: Es una conexión en forma de cadena por ejemplo para BBDD clusterizadas.
URI de conexión: Cadena con los parámetros de conexión a la BBDD.
Nombre de la colección de datos
Intervalo de actualización: El dataset se puede actualizar automáticamente cada cierto intervalo de tiempo, eligiendo la cantidad de minutos, horas, días, semanas o meses, así como la hora de inicio de la ejecución (excepto para minutos u horas, donde se toma como referencia la hora de creación/actualización anterior del dataset).
Consulta: "Consulta" con la que se quiera recuperar los datos, siguiendo el paradigma MapReduce de MongoDB.
InfluxDB
Se debe cumplimentar la información relativa a la conexión:
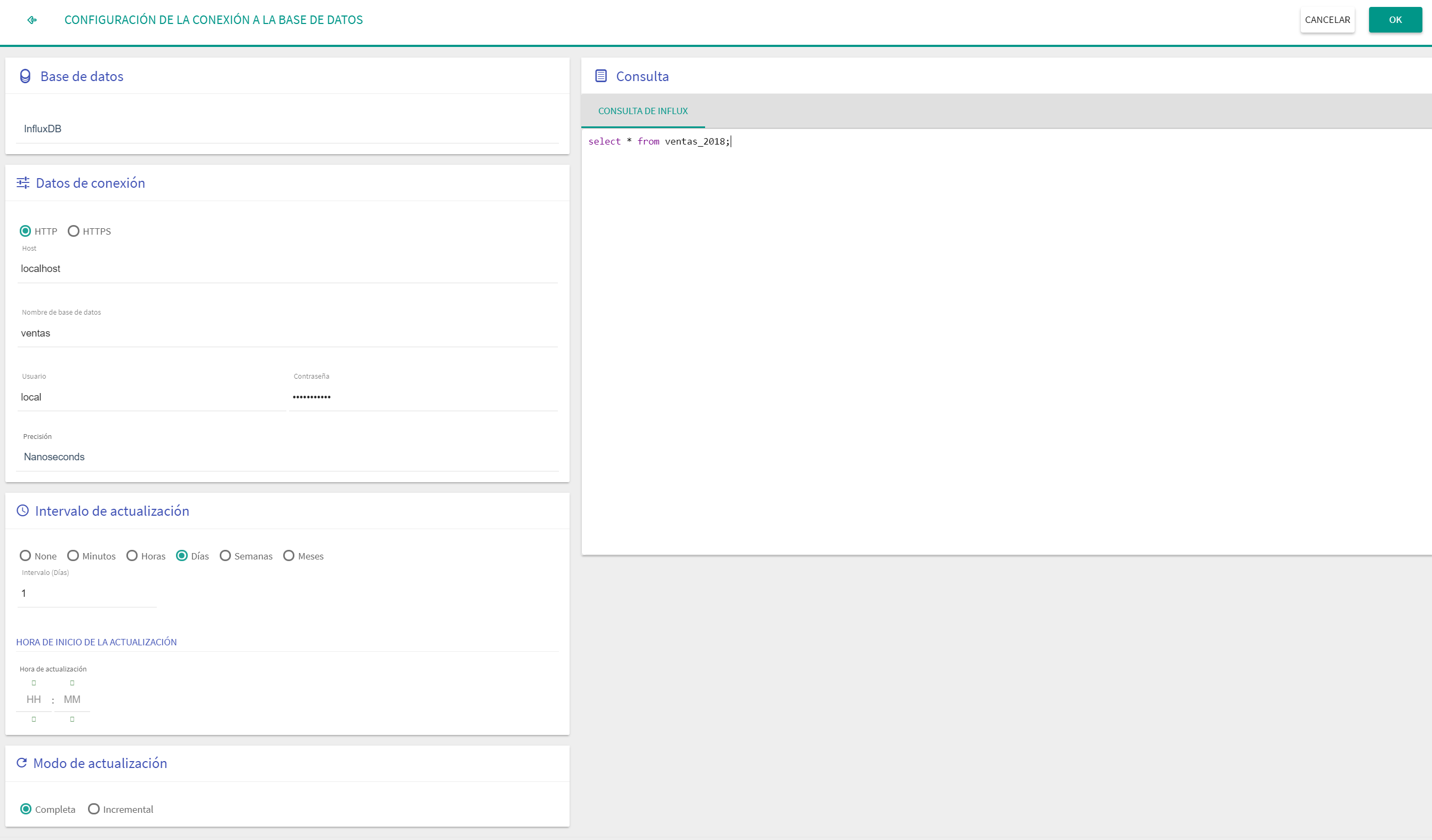
Protocolo: Se realiza la conexión por protocolo HTTP o HTTPS.
Host: Dirección IP donde se encuentra la base de datos. Si el puerto en el que escucha la base de datos no es el puerto por defecto se puede añadir a continuación del host separandolo por ":", por ejemplo
localhost:8087.Nombre de la base de datos
Usuario: Usuario con permiso de lectura en la base de datos.
Contraseña
Precisión: Permite indicar la precisión de la dimensión temporal.
Intervalo de actualización: El dataset se puede actualizar automáticamente cada cierto intervalo de tiempo, eligiendo la cantidad de minutos, horas, días, semanas o meses, así como la hora de inicio de la ejecución (excepto para minutos u horas, donde se toma como referencia la hora de creación/actualización anterior del dataset).
Consulta: Consulta con la que se quiera recuperar los datos, siguiendo la sintaxis SQL de InfluxDB.
Tabulae permite además realizar dos tipos de atualización:
Completa: La actualización completa permite volcar todos los datos que devuelve la consulta sustituyendo completamente el contenido del dataset.
Incremental: Se realiza una actualización incremental que mueve al dataset sólo una parte de los datos disponibles en la base de datos original. Este tipo de actualización es el recomendable cuando el volumen de datos a mover es elevado. La condición incremental se resuelve indicando:
Columna incremental: En el caso de InfluxDB el campo incremental necesariamente es el campo fecha o time, que ya aparece fijado por defecto.
Variable: Es la variable que utiliza internamente tabulae para almacenar el último valor obtenido desde la base de datos original. El valor por defecto es $last_value$ y generalmente no hay que modificarlo. Se permite editarlo únicamente por si hubiese que aplicar alguna función específica a dicho valor.
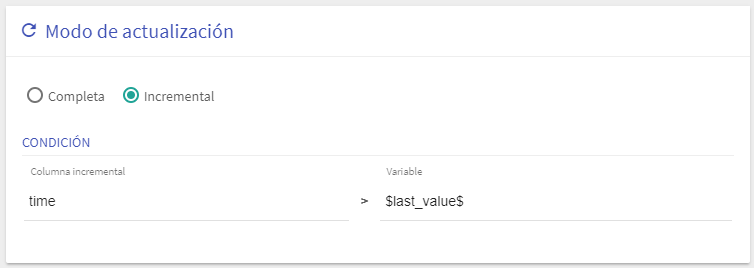
Imagen - Configuración de la condición para actualizaciones incrementales Añadir a la sentencia SQL de InfluxDB una clausula "where $condition$". El sistema se encargará de sustituir la variable $condition$ por la condición adecuada en cada caso para obtener únicamente los datos que hayan sido añadidos desde la última sincronización.
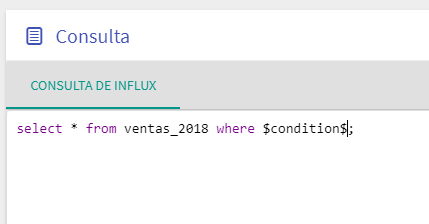
Imagen - Configuración de la consulta para actualizaciones incrementales
Desde Google Drive
Una vez seleccionada esta opción, Google, pide las credenciales de usuario de Google Drive para seleccionar el fichero que se quiere importar.
Warning Puede ocurrir que el navegador bloquee los popups de login de Google. Para un correcto funcionamiento hay que permitir el popup en esta página.
Desde Google Analytics
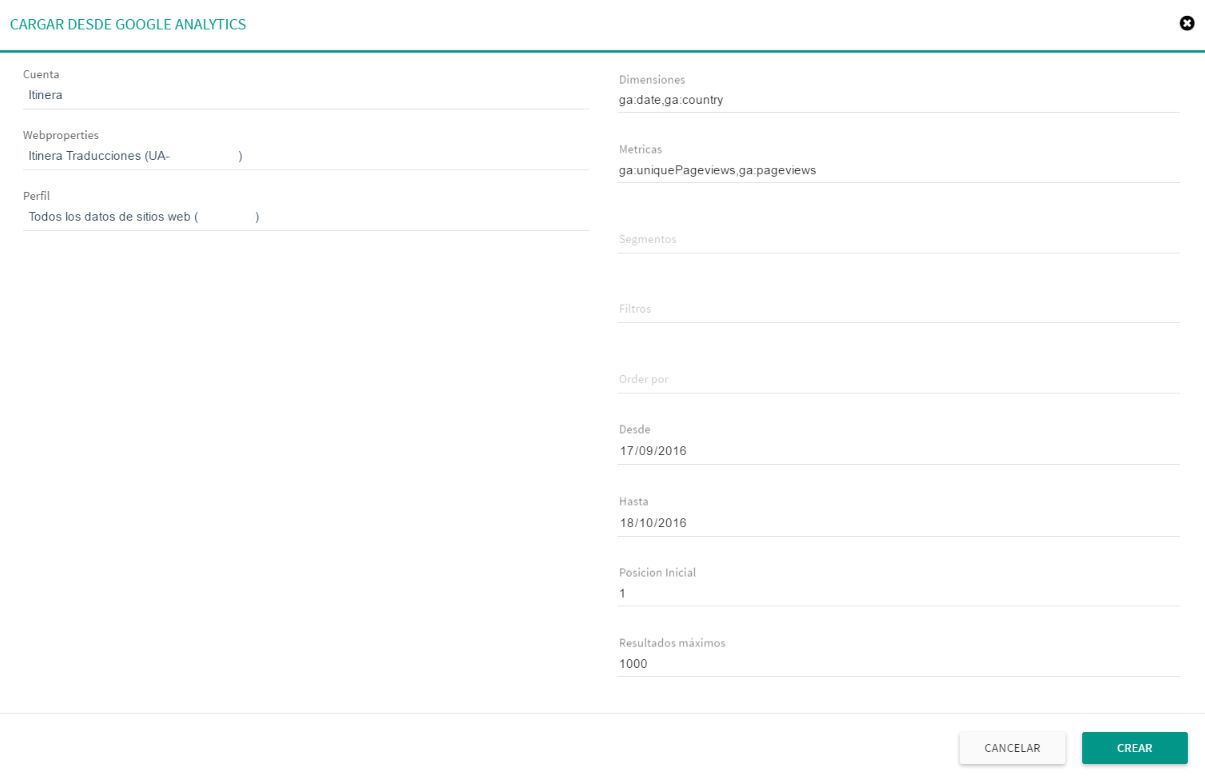
En el diálogo de importación desde Google Analytics se tienen que cumplimentar las siguientes opciones:
Cuenta: Cuenta de Google Analytics que quieres utilizar.
Webproperty: Indica que webproperty de la cuenta seleccionada quieres utilizar.
Perfil: Perfil que se quiere analizar.
Datos de consulta: En esta sección se pueden incorporar todos los parámetros necesarios para realizar una consulta a Google Analytics: Dimensiones, Métricas, Segmentos, Filtros, Orden, Desde y hasta, Posición inicial y Número de resultados.
Info Se dispone de más información sobre los datos de consulta en este enlace: Google Analytics Query Explorer .
Desde otro dataset
Se puede crear directamente un dataset como una "vista" de otro dataset o de un dataset público (esta opción también se puede invocar desde la funcionalidad Filtrar/Agregar de un dataset existente, que se verá más adelante). Para ello se tendrá que construir una consulta de agregación utilizando el diálogo de consulta y agregación de datasets, que se explica en la sección Diálogo de consultas. Los usuarios avanzados también pueden crear un dataset a partir de una consulta especial MapReduce.
Cuando un dataset se crea a partir de otro se genera una relación o ligadura "padre-hijo", es decir, los campos del "hijo" heredan la estructura de los campos originales del "padre" (identificador, tipo de datos, etc.). Esto permite que el hijo se pueda actualizar si se actualiza el padre y también que ambos datasets respondan de igual forma a un filtro global.
Warning Cuando se incluye un campo de naturaleza fórmula en la consulta de creación de un nuevo dataset (hijo) el campo continua siendo una fórmula si se han incluido todos los campos de los que depende. En caso contrario el campo, aunque está presente en el dataset hijo, se persiste, es decir, se cálcula y se guarda con los valores calculados. Pierde por tanto la naturaleza de fórmula ya que está no se puede resolver en el nuevo dataset.