Diálogo de consultas
El diálogo de consultas permite seleccionar, agrupar y filtrar los datos de un dataset para adaptarlos a las necesidades de visualización que se quieran implementar.
Por ejemplo, si se tiene un dataset con los datos de población por municipios desde el año 2000, pero solo se quieren ver los datos de los últimos 5 años, y además obtener el valor total y no por municipio, se utilizará el diálogo para crear una consulta que devuelva los datos requeridos.
El diálogo de consultas de Tabulae permite hacer consultas tanto sencillas como muy complejas sobre la misma base, ya que se estructura en bloques que se van añadiendo a voluntad. Un usuario normal puede resolver su consulta en uno o dos bloques sin más complicación, mientras que usuarios avanzados con datasets complejos pueden usar un número elevado de bloques.
Se puede resumir en tres puntos la clase de consultas que realiza Tabulae:
Las operaciones sobre el dataset son registro a registro, es decir, se empieza a leer por la primera fila del dataset y se opera en cada fila sucesivamente hasta llegar a la última.
Los bloques de la consulta se resuelven secuencialmente, es decir, sobre un dataset se van aplicando de forma ordenada las partes conceptuales de la consulta, de tal forma que la entrada del primer bloque es el dataset completo, y el resultado salida de un bloque es la entrada del siguiente bloque (en caso de haber más de un bloque). El resultado del último bloque es el resultado de la consulta.
Existen limitaciones sobre las consultas: por defecto no es posible realizar cruces o joins entre datasets diferentes, así como tampoco combinar diferentes consultas ni realizar agregados con funciones de ventana sobre un mismo datasets para dar un único resultado. Se dispone no obstante de dos funcionalidades avanzadas que pueden ayudar a realizar ciertas operaciones como las anteriores
La sección se divide en dos partes:
Estructura general de la consulta: Se detalla la estructura de las consultas en Tabulae y los bloques básicos que la componen.
Consultas especiales: Aquí se describen dos consultas especiales que permiten solventar en parte las limitaciones comentadas.
Subconsultas o subqueries: Análogas a la consulta general, permiten combinar información de varias consultas (esto es, realizar un cruces o joins), pero con un alcance limitado.
MapReduce: Esta opción da la posibilidad de programar una consulta usando la funcionalidad MapReduce de MongoDB, lo cual permite escalar consultas sobre muchos millones de registros. Como bonus permite realizar operaciones multiregistro en la misma consulta.
Estructura de una consulta
El primer paso de la consulta será seleccionar (por nombre) el dataset que se quiere utilizar. Al escribir aparecerá una lista con las opciones que concuerdan y habrá que hacer clic sobre una de ellas.
Una vez seleccionado el dataset se empezará a implementar la consulta por bloques. Por defecto siempre se presentan dos bloques: el primero de filtrar y el segundo de agrupar, pero no es más que una sugerencia para comenzar. Se pueden añadir más bloques haciendo clic en el botón (en cualquiera de los bloques, se añadirá uno a continuación), o bien eliminar cualquiera de los ya presentes haciendo clic en el botón . Siempre se puede restaurar la configuración por defecto haciendo clic en el botón .
Las diferentes tipos de bloques disponibles son los siguientes:
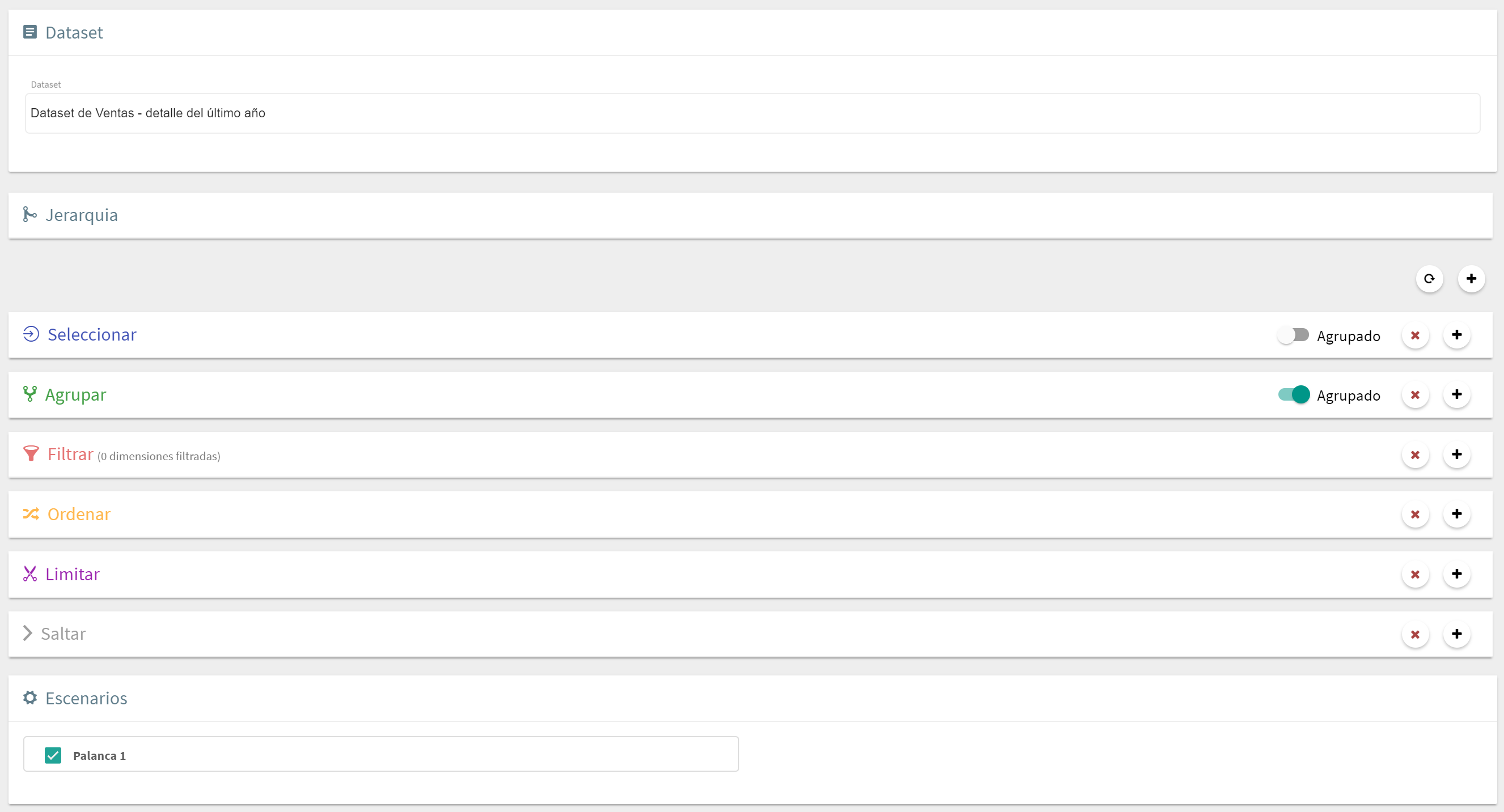
Bloque seleccionar: Permite seleccionar y crear fórmulas.
Bloque agrupar: Permite agrupar los datos.
Bloque filtrar: Permite filtrar los datos.
Bloque ordenar: Permite ordenar los registros.
Bloque limitar: Permite limitar el número de registros devueltos.
Bloque saltar: Permite saltar los primeros n registros.
Bloque jerarquía: Permite incluir una relación jerárquica en la consulta.
Bloque escenario: Permite incluir escenarios (palancas) en un filtro global.
Combinando estos bloques se podrán realizar consultas tanto sencillas como muy complejas.
Bloque Seleccionar
Este bloque permite seleccionar las dimensiones y medidas, de todas las disponibles en el dataset, que que se van a mostrar en la visualización. Se pueden marcar y desmarcar las que se deseen, teniendo en cuenta que si se desmarca un campo éste no podrá ser utilizado en los bloques posteriores.
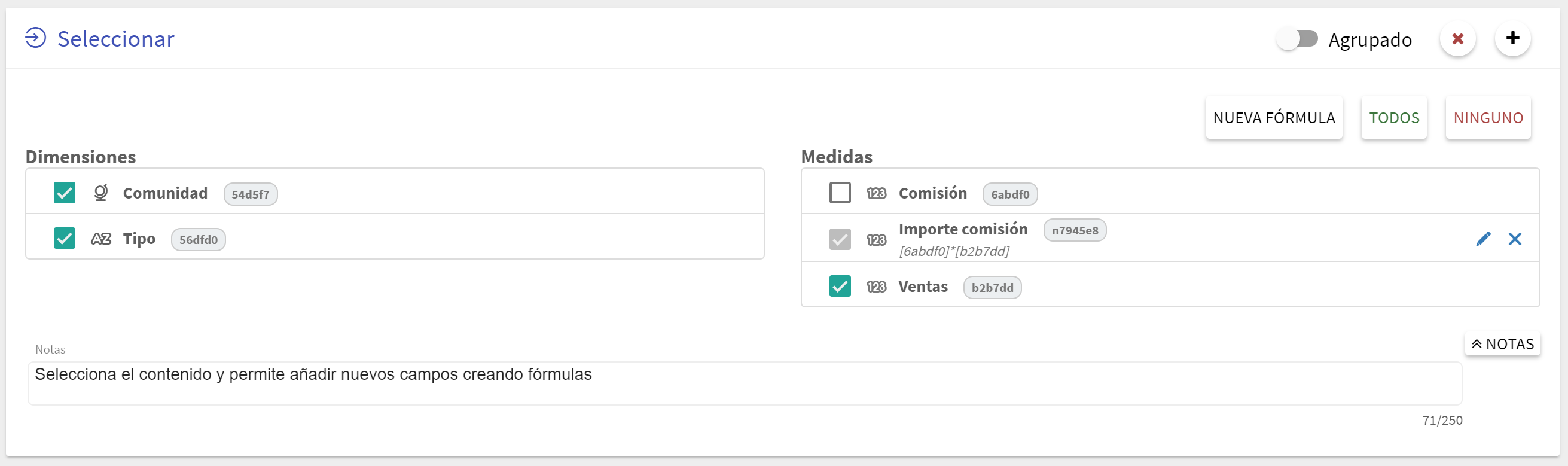
Info Con valor informativo, al lado del nombre de la dimensión/medida aparece su identificador interno y su tipo de dato.
Además en este bloque es donde se pueden añadir nuevos campos fórmula, creados a partir de operaciones y funciones sobre los campos disponibles. Para ello solo hay que hacer clic en el botón de "Nueva fórmula", y se abrirá el diálogo de creación de fórmulas (ver sección de Fórmulas).
Para editar una fórmula ya creada hay que hacer clic el icono , y para eliminarla en el icono , ambos situados a la derecha del campo fórmula.
Warning Las fórmulas solo pueden ser editadas dentro del bloque en el que se añadieron.
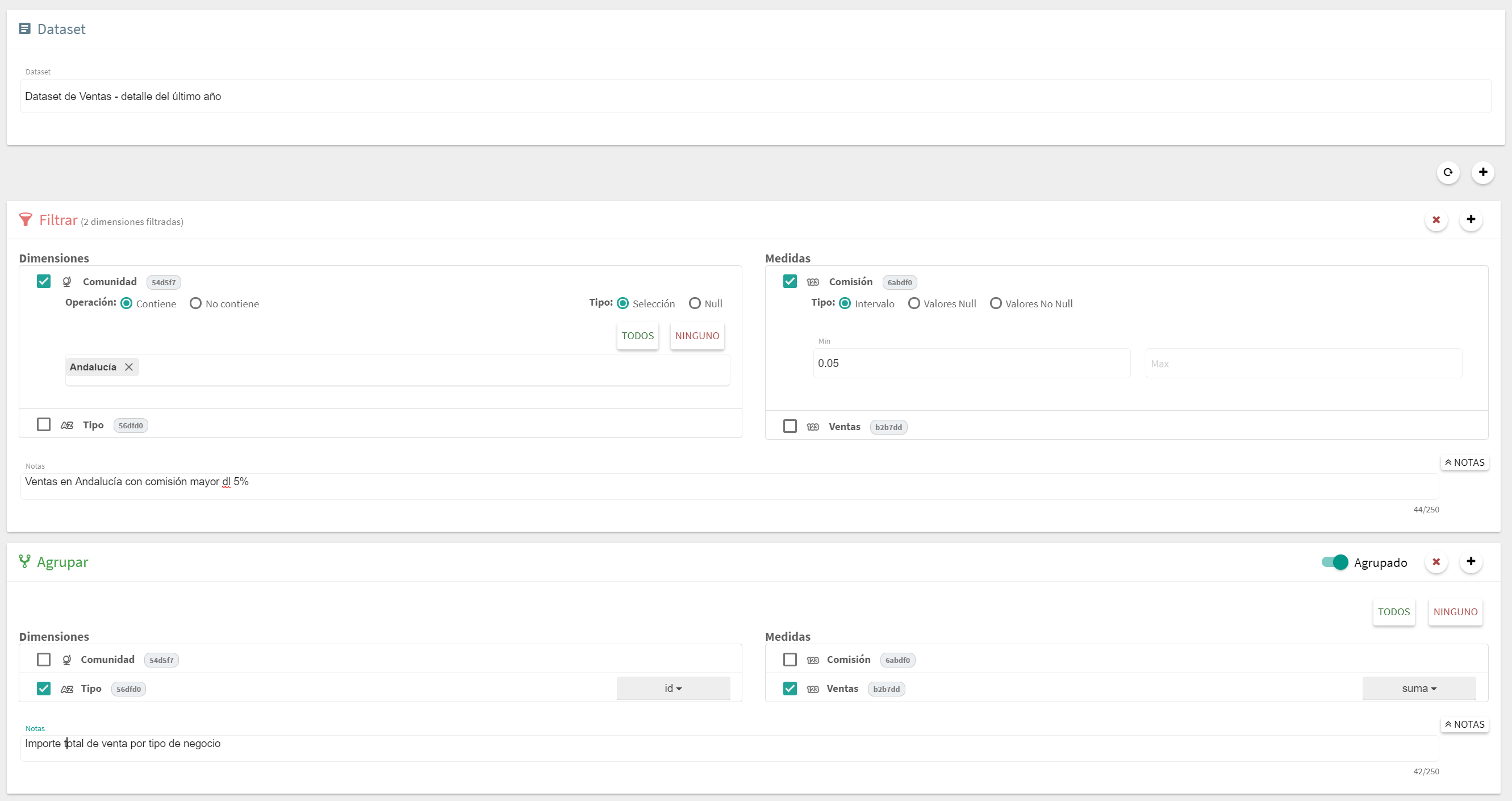
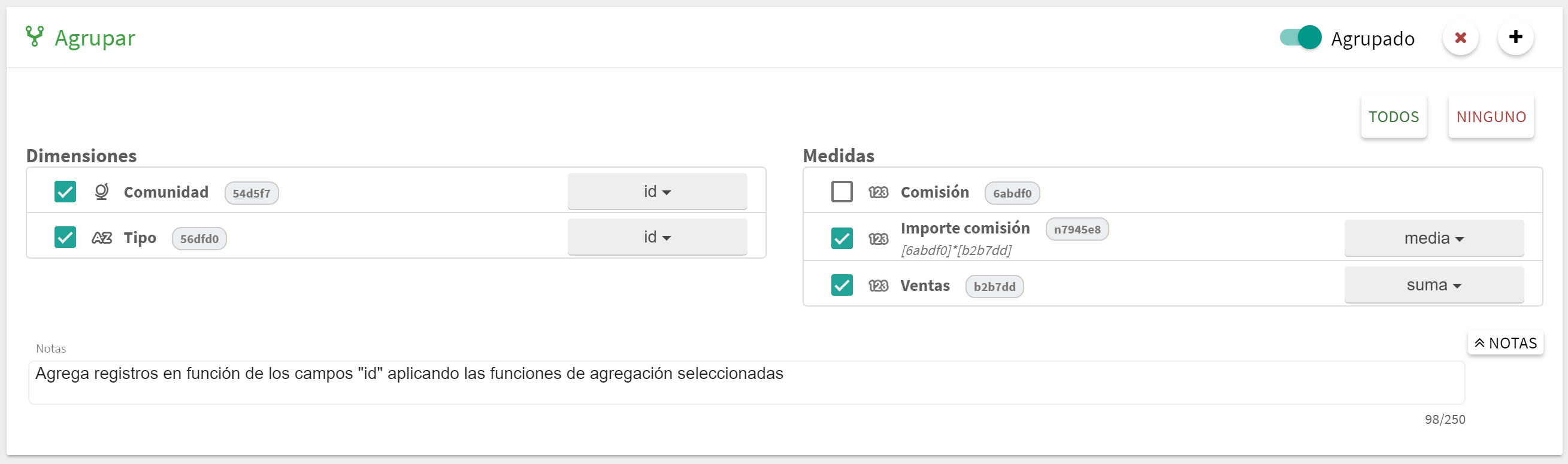
Bloque Agrupar
Este bloque permite agrupar los datos en función de los valores de los campos seleccionados. El primer paso que se tiene que realizar es marcar las dimensiones y medidas que se quieren utilizar. Como ocurría con el bloque Seleccionar, si una dimensión no esta marcada no podrá ser utiliza en los siguientes bloques.
Info Se puede convertir un bloque seleccionar en un bloque agrupar, y viceversa, activando o desactivando el pulsador de "agrupado"
El comportamiento del agrupado será diferente en función de la naturaleza del campo:
Dimensiones
Una vez marcadas los componentes se debe seleccionar las funciones de agregación para el conjunto de dimensiones. Se dispone de las siguientes funciones:
id: Indica que se quiere usar esta dimensión para agregar. Es decir, por cada valor diferente de esta dimensión se creara un nuevo grupo.
primero: Indica que se tomará el primer valor de esta dimensión para cada uno de los grupos creados.
último: Indica que se tomará el último valor de esta dimensión para cada uno de los grupos creados.
mínimo: Indica que se tomará el mínimo valor de esta dimensión para cada uno de los grupos creados.
máximo: Indica que se tomará el máximo valor de esta dimensión par cada uno de los grupos creados.
Warning En los casos primero y último es importante el orden en el que llegan los valores al bloque. Para no cometer errores es conveniente ordenar los valores con el criterio deseado (por ejemplo con un bloque Ordenar) previamente al bloque Agrupar.
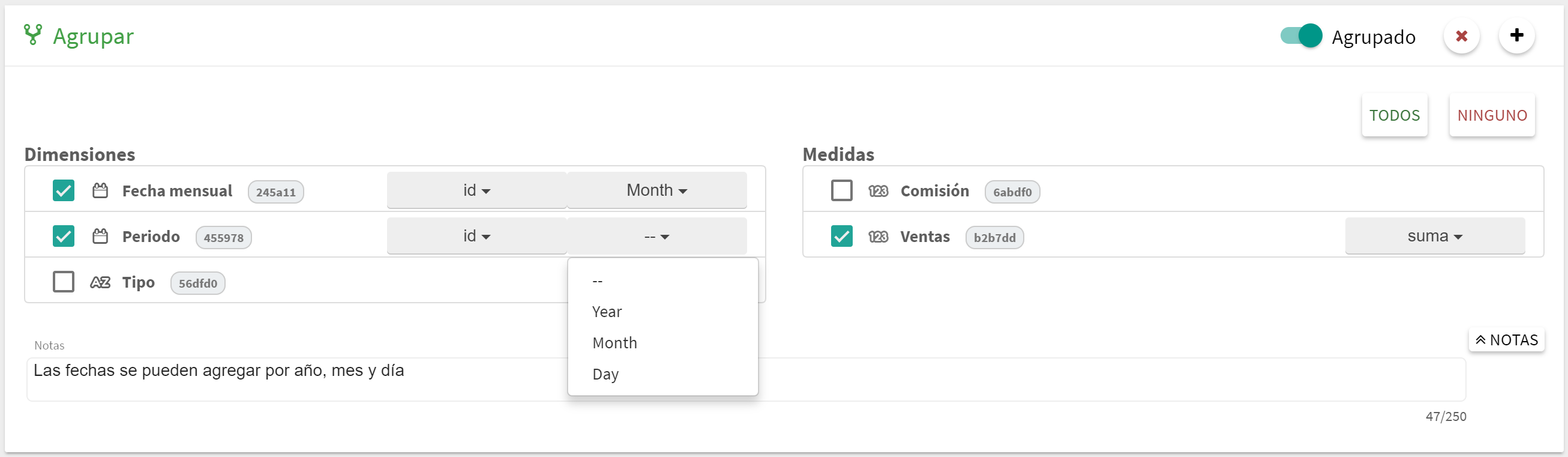
En el caso de las dimensiones de tipo fecha se dispone de un segundo combo que nos permite agrupar los valores de esa dimensión a nivel de día, mes o año.
Medidas
El último paso es definir la función de agregación para cada una de las medidas seleccionadas, es decir, que operación se quiere hacer con todos los valores que se agrupen dentro del mismo grupo. Se dispone de las siguientes funciones de agregación:
suma: Realiza la suma de los valores de cada grupo. En caso de haber valores nulos éstos se sustituyen por 0.
Warning Como los nulos se sustituyen por 0 para el agregado suma, si todos los valores de un grupo son nulos la operación devolverá 0 y no null.
media: Realiza la media de los valores de cada grupo. En caso de haber valores nulos éstos se ignoran para la media, esto es, se hará la media de los
N - Mvalores no nulos, siendoNel número total de valores yMel número de valores nulos. Si todos los valores son nulos se devuelve null.contar: Cuenta el número de registros de cada grupo (independiente del valor que tengan).
mínimo: Selecciona el mínimo de los valores de cada grupo. En caso de haber valores nulos éstos se ignoran, y se devolverá el mínimo de los valores no nulos. Si todos los valores son nulos se devuelve null.
máximo: Selecciona el máximo de los valores de cada grupo. En caso de haber valores nulos éstos se ignoran, y se devolverá el máximo de los valores no nulos. Si todos los valores son nulos se devuelve null.
primero: Selecciona el valor del primer registro de cada grupo.
último: Selecciona el valor del último registro de cada grupo.
desviación típica: Realiza la desviación típica para cada grupo. En caso de haber valores nulos éstos se ignoran para la desviación típica, esto es, se hará la desviación típica de los
N - Mvalores no nulos, siendoNel número total de valores yMel número de valores nulos. Si todos los valores son nulos se devuelve null.recalcular: Sólo aplica para fórmulas. En este caso se aplica la fórmula después de agregar: en un primer paso se agregan todas las dimensiones y medidas con sus respectivas funciones de agregación excepto las medidas con la opción de recalcular, y a continuación, una vez se tiene el primer resultado se aplican la fórmulas con los valores originales ya agregados.
Warning Si la fórmula que se recalcula depende de medidas que no se incluyen explicitamente en el agregado, éstas serán calculadas de forma autómatica por Tabulae con la función de agregación suma.
id: Indica que se quiere usar esta medida para agregar, al igual que sucede con las dimensiones. Es decir, por cada valor diferente de la medida se creara un nuevo grupo.
Warning El orden de los registros tras un agrupado no tiene que ver con el orden previo al mismo, esto es, si una dimensión está ordenada con cierto criterio previamente al bloque Agrupar éste se pierde al hacer un agrupado.
Bloque Filtrar
Este tipo de bloque permite definir filtros sobre los registros para seleccionar solo aquellos que se quiere utilizar. Para ello se muestra una lista de las diferentes dimensiones y medidas disponibles en el dataset. Se debe marcar la caja de las dimensiones que se quieren utilizar en el filtro. Los datos necesarios para filtrar un registro dependen del tipo de dimensión.
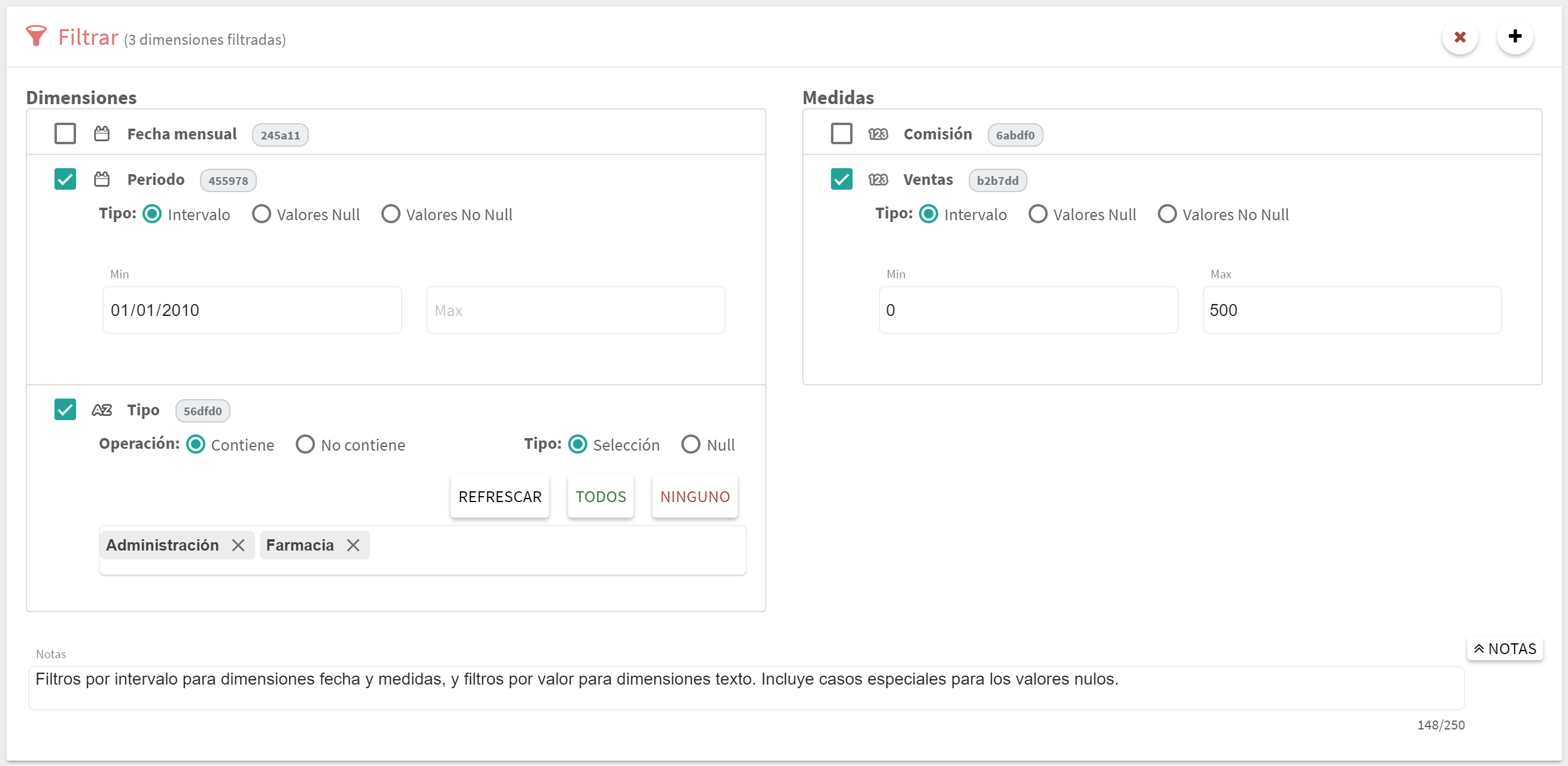
Hay dos tipos de clases de filtro:
Filtros por valores
Este tipo de filtros permiten definir los valores permitidos dentro del conjunto total de valores de una dimensión. Son utilizados por las dimensiones de tipo cadena de texto o georef.
Una vez seleccionada la dimensión se mostrará un caja de texto que permitirá ir escribiendo los valores permitidos. Cada vez que se escribe un nuevo valor se debe pulsar "Enter" para que este valor sea añadido a la lista. Para quitar un valor ya añadido, simplemente hay que hacer clic en la dentro del elemento, y para añadir/quitar de forma masiva se dispone de los botones "Todos" y "Ninguno". El botón "Refrescar" permite volver a leer los diferentes valores, en caso de que se haya podido actualizar el contenido del dataset.
Una vez seleccionados los valores deseados, se dispone de dos botones a la izquierda con los que se elige si los valores seleccionados son aquellos usados ("Contiene") o descartados ("No contiene"). Además, para tratar el caso especial de valores nulos, en la parte derecha se habilita una selección de filtro para valores null o empty, ya que este valor especial (la "falta" de valor) no aparece dentro del conjunto de valores disponibles.
Filtro por límites
Este tipo de filtro es usado con las medidas y fechas, y simplemente precisa alguno de los límites mínimo y máximo. Estos valores son opcionales, de modo que se puede definir el mínimo y dejar en blanco el máximo y viceversa. En el caso de las dimensiones de tipo fecha se podrán introducir estos límites usando los controles de tipo calendario ofrecidos.
Bloque Ordenar
Este tipo de bloque permite ordenar los resultados de la consulta. Es posible ordenar los resultados por 1 o varias columnas. Para ello, en la lista de dimensiones, se marca el checkbox de las dimensiones que se quieren utilizar para ordenar, y a continuación se ordenan dentro de la lista arrastrándolas, usando el drag and drop. En el combo disponible en cada componente seleccionado se podrá marcar la dirección del orden, ascendente (de menor a mayor, comenzando por los nulos) o descendente.

Info Las dimensiones que no estén seleccionadas no hay que ordenarlas, ya que se ignorarán.
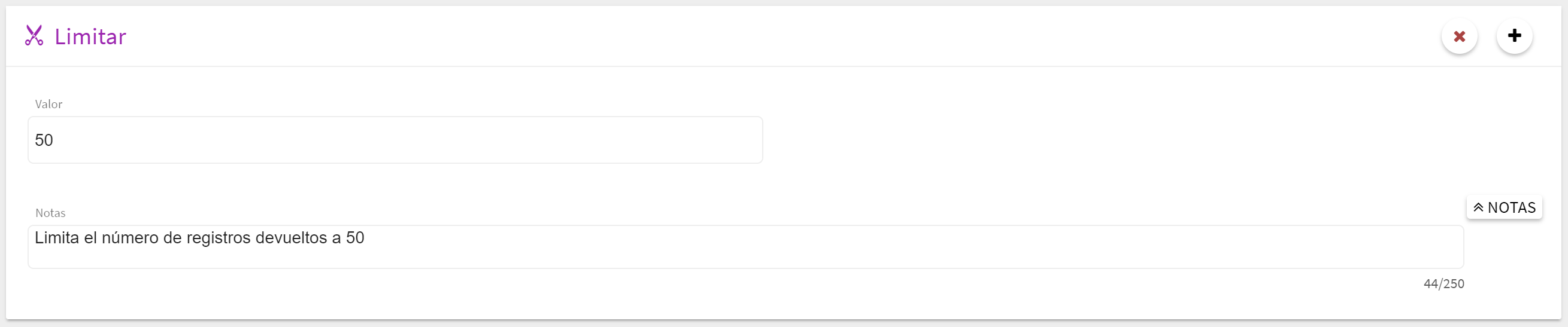
Bloque Limitar
Este bloque permite limitar el numero de registros que devuelve la consulta. Por ejemplo, para hacer un top 10 se puede limitar estos resultados a los 10 primeros. El valor numérico se escribe directamente en el espacio habilitado para ello.
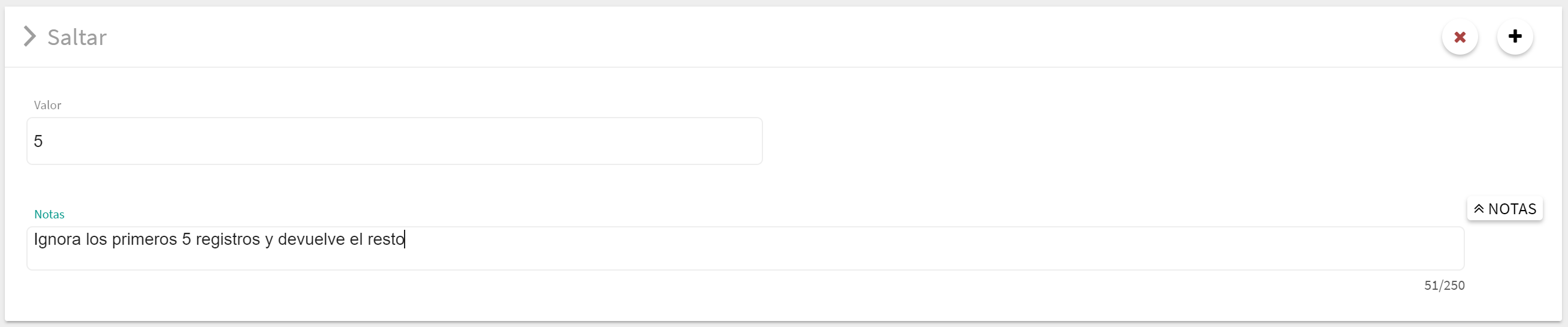
Bloque Saltar
Permite omitir los primeros n valores de la consulta. Esta operación es muy útil, por ejemplo, para paginar los resultados. El valor numérico se escribe directamente en el espacio habilitado para ello. De este modo podemos, por ejemplo, devolver los registros del 11 al 20 usando primero un bloque Saltar con valor 10 y después un Bloque Limitar con valor 10.
Bloque Jerarquía
Este bloque aparece en el diálogo de consulta que se habilita para los widgets tabla drilldown, gráfica, y filtros globales o combos. En el caso de tablas drilldown automáticamente solo será posible elegir un dataset que tenga definida alguna jerarquía (ya que es obligatoría), mientras que en el caso de los filtros o gráficas se puede elegir cualquiera, y el uso de la jerarquía será opcional. Una vez elegido el dataset, el primer bloque de la consulta corresponderá a la selección de una de las jerarquías definidas para ese dataset. El resto de la consulta se podrá realizar combinando el resto de bloques conforme se quiera. Para que haya realmente drilldown, es necesario incluir al menos dos campos de la jerarquía en el resultado final de la consulta, y que así haya un primer nivel que se despliega en un segundo nivel (sino, aunque se use una jerarquía, no habrá niveles dependientes). A partir de ahí se pueden seleccionar tantos campos de la jerarquía como se desee, no siendo necesario seleccionarlos todos los incluidos en ella.
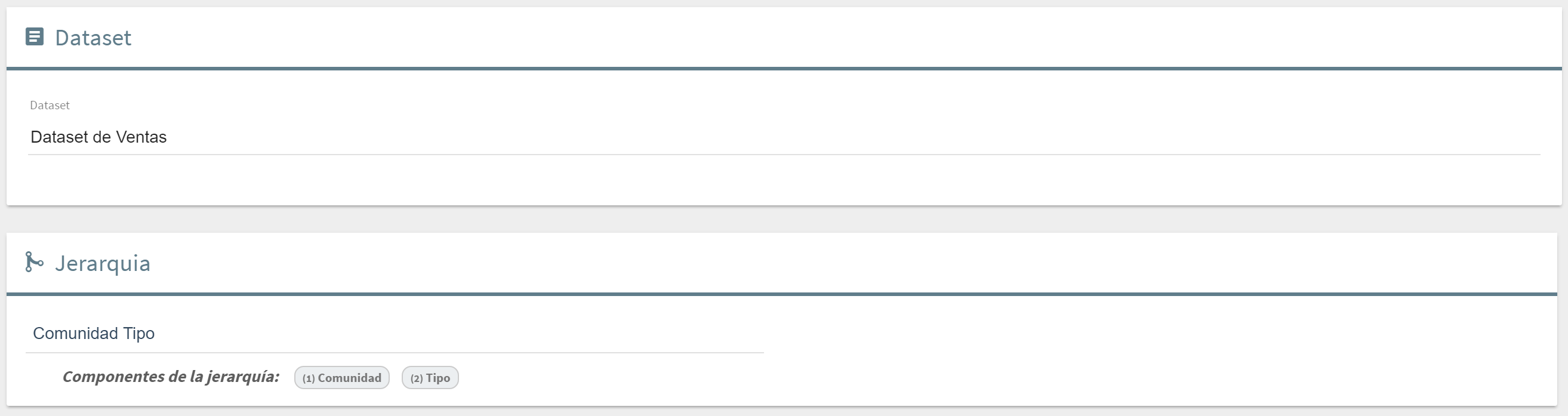
Ejemplo: si una jerarquía está definida por los campos Comunidad + Provincia + Municipio, y en la consulta se selecciona Comunidad y Provincia, el drilldown tendrá dos niveles. Por tanto en la tabla aparecerá un primer nivel con las Comunidades, y cada fila se podrá desplegar apareciendo información de las Provincias que "pertenecen" a esa Comunidad.
Bloque Escenario
Este bloque solamente aparece en el diálogo de consulta que se habilita para un filtro global o un filtro de combos dentro de un dashboard. No precisa incluir ningún dataset, ya que los escenarios o palancas está definidos de forma global para cada pestaña de la aplicación (aunque no excluye el que se puedan incluir otras dimensiones o medidas en el mismo filtro).
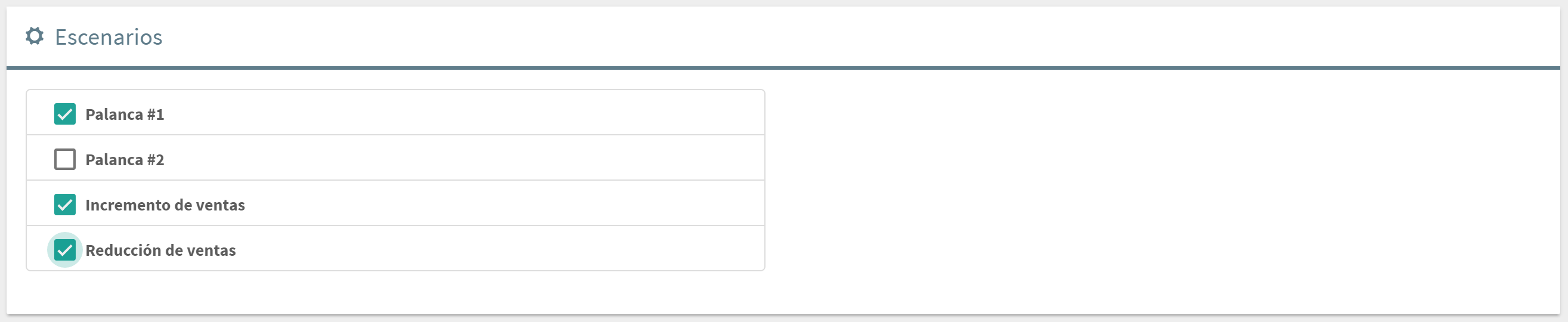
Permite incluir las palancas simplemente habilitando las deseadas. Éstas se situarán en la parte superior del filtro, en el mismo orden en el que se hayan ido añadiendo a la app.
Consultas especiales
Las consultas especiales son añadidos que permiten solventar en parte las limitaciones que presenta la consulta general de Tabulae. Actualmente hay de dos tipos:
Subconsultas
Los datos en Tabulae siempre se visualizan en widgets dentro de aplicaciones, y cada widget incorpora la información mediante una consulta. Cada consulta referencia a un único dataset, por tanto toda la información, datos o valores que se quieren usar tienen que estar a priori en el dataset. Esto puede generar que para tener en un dataset toda la información que se requiere para la visualización haya grandes complicaciones. En ocasiones, el hacer una consulta auxiliar sobre el mismo u otro dataset permite resolver de forma muy simple el problema.
En esta subsección se revisarán los siguientes puntos:
Consultas auxiliares: Ejemplo práctico de como surge la necesidad de consultas auxiliares.
Creación y edición de subconsultas: Como crear una subconsulta o subquery.
Uso de filtros globales: Cómo relacionar subconsultas con filtros globales en dashboards.
Consultas auxiliares
La necesidad de usar juntos los resultados de dos consultas puede surgir en ejemplos muy sencillos.
Ejemplo: Un dataset contiene la población de los municipios de una región. Se quiere generar una consulta que diga el % de la población de cada municipio respecto del total de la región. La consulta, conceptualmente, se divide en tres partes:
- La primera, que obtiene la población total agregada (la suma de todos los municipios).
- La segunda, que obtiene la población de cada municipio.
- La tercera, que divide el valor propio de cada municipio por el valor total (y multiplica por 100, para obtener %).
Las partes primera y segunda son incompatibles en un proceso secuencial, ambas son diferentes agregados de la información inicial, por tanto se tienen que calcular por separado, y después combinar para obtener el resultado requerido.
Una subconsulta o subquery es exactamente una consulta que retorna una fila. Es decir, la subconsulta se desarrolla exactamente igual a una consulta de un widget cualquiera, pero al final se aplica obligatoriamente un limitar. Sobre las columnas o campos no hay ninguna restricción, se pueden tantos campos que se quiera.
Estos valores son globales ya que se podrán usar en cualquier widget de una pestaña/sección, incorporándolos a través de variables en fórmulas.
Creación/edición de una subconsulta
En una app, al hacer clic en el icono de la barra de herramientas, aparece la opción de gestión de las subconsultas .
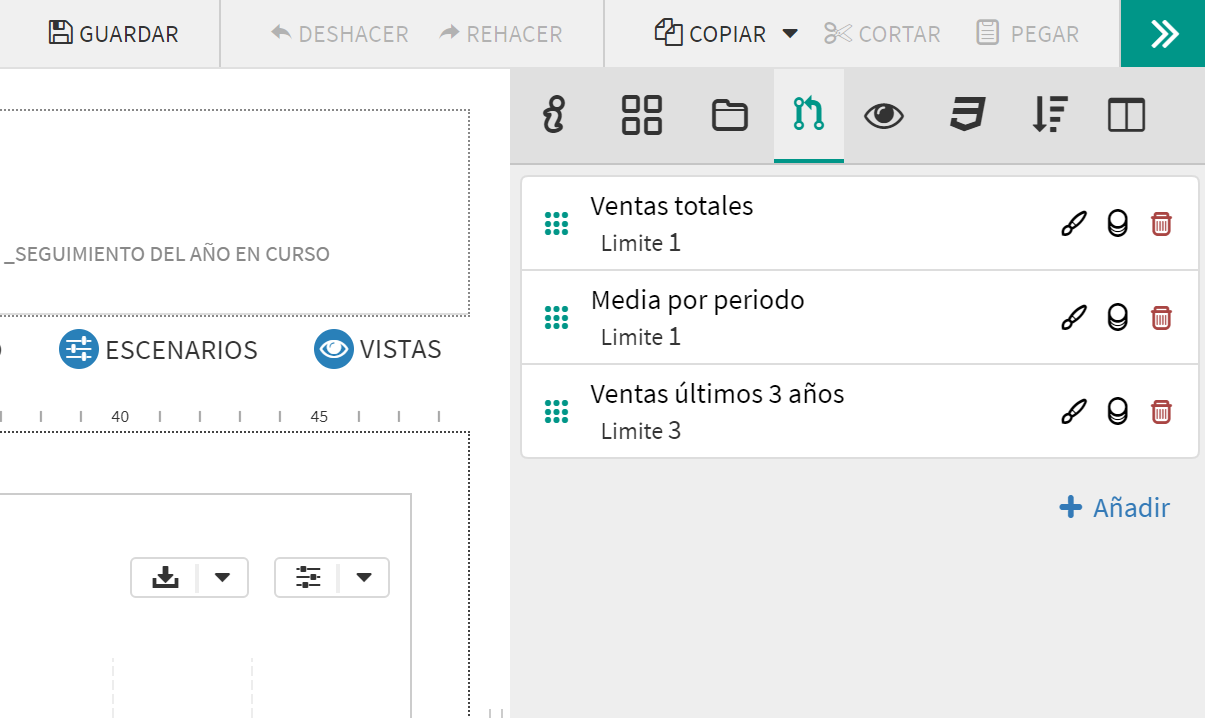
Para crear una nueva subconsulta no hay más que hacer clic en el botón "Añadir" en la parte inferior derecha del menú. De igual modo, si ya hay subconsultas creadas, se pueden editar y modificar si se hace clic en el icono a la derecha del nombre de la subconsulta. En ambos casos aparecerá el diálogo de consultas descrito anteriormente en la primera parte de esta sección. La única particularidad será el final de la consulta, aparece un nuevo bloque donde se indican las siguientes opciones:
Limitar: Obligatoriamente se fija un limitar con valor máximo 10 registros.
En caso de generar una subconsulta que se va a invocar en una fórmula en un widget solo se considera el primer registro de la misma. Por ello, y de forma más habitual, la subconsulta se limita a 1 registro. Es importante tener en cuenta este punto para no realizar una consulta que retorne multiples registros, ya que en ese caso solamente se tomará el primero de acuerdo al orden con el que lleguen los registros a final de la consulta.
En caso de generar una consulta para invocar desde las anotaciones de un gráfico se pueden incluir hasta un máximo de 10 registros.
Nombre de la subconsulta: Se puede fijar un nombre descriptivo asociado a la subconsulta (por defecto se le asocia un nombre igual a su id interno).
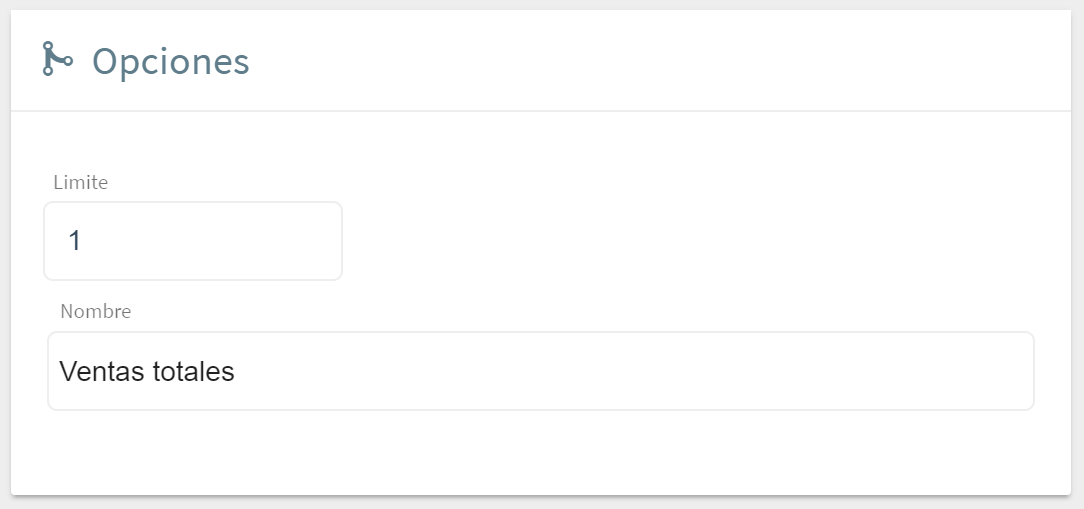
Ejemplo: Continuando con el ejemplo anterior, el primer paso se podría realizar con una subconsulta, donde se obtendría la población total de la región, esto es, un número sencillo que se puede usar de forma global. Esta subconsulta se llamará "población total", por ejemplo.
Con esta población total, en un widget se hace una consulta donde se obtiene en un primer paso la población por municipio (esto es, una dimensión "municipio" y una medida "población, y en un segundo paso (bloque seleccionar) se hace una fórmula igual a la división de la medida "población" por la variable "población total", que se obtiene con una subconsulta. Esta fórmula es una medida con el valor que se desea, la población porcentual por municipio respecto del total de la región.
Uso de filtros globales
En el caso de aplicaciones de tipo dashboard se pueden usar filtros en una pestaña. Éstos no son más que selectores de valores que afectan a los diferentes widgets de la pestaña, reduciendo los registros utiles de un dataset a aquellos cuyos valores están seleccionados en los filtros. De igual modo, una subconsulta puede verse afectada por los filtros o no. Para controlar este hecho en el menú de las subconsultas hay que hacer clic en el icono a la derecha del nombre de la subquery, el cual da acceso a la personalización de la subconsulta.
Al acceder a la pesonalización se puede habilitar la opción de "Usar filtros globales". En caso de no estar habilitada los filtros globales no afectan a la subconsulta, ésta se obtendrá sobre el total de registros del dataset elegido. En caso de estar habilitada aparece un menú con todos los filtros presentes en la pestaña, y en cada filtro los campos sobre los que se permite hacer una selección. Para cada campo se puede decidir entre tres opciones:
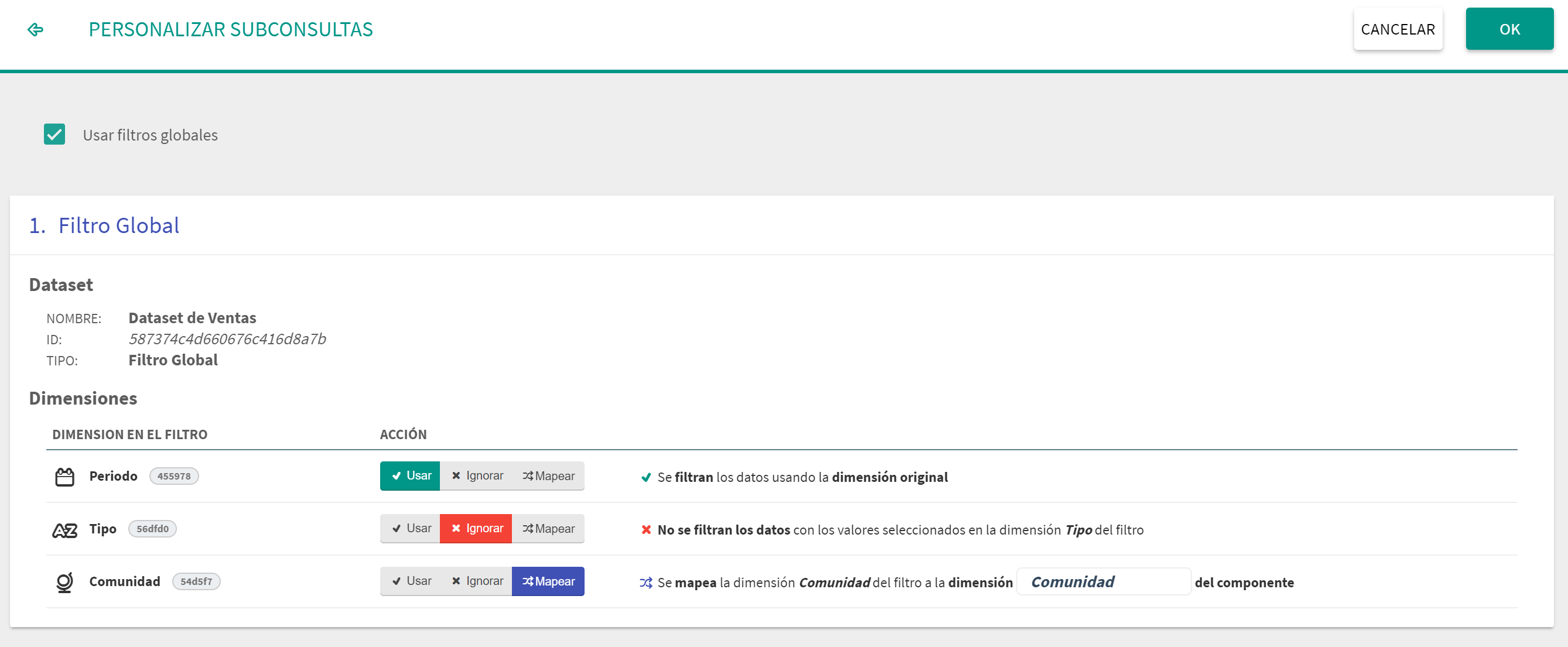
El campo afecta directamente a la subconsulta: si el dataset de filtro y el de la subconsulta es el mimsmo la selección del filtro aplica a la subconsulta.
El campo no afecta a la subconsulta, la selección de valores de ese campo se ignora en la consulta que genera esta.
El filtro está asociado a un dataset diferente al de la subconsulta, por lo que directamente no puede afectar a la subconsulta. Esta opción permite hacer un redireccionamiento para relacionar dos campos de dos datasets diferentes, de forma que el filtro sí pueda afectar a la subconsulta. Un desplegable permite seleccionar el campo del dataset de la subconsulta que se relacionará con el campo del filtro.
Consultas MapReduce
Tabulae guarda la información de datasets y apps y trabaja internamente con la base de datos NoSql MongoDB. Como ésta cuenta con una funcionalidad MapReduce, Tabulae dispone una interfaz que permite a los usuarios programar las consultas directamente en el formato MapReduce si así lo desean, y poder así sacar todo el partido de las técnicas Map y Reduce para tratar grandes volumenes de datos o bien poder realizar procesos de consulta complejos que no son posibles con la consulta general de Tabulae.
Se describe a continuación la interfaz MapReduce de Tabulae:
Está disponible actualmente solo para creación de datasets a partir de otros datasets o a partir de conexión a una BBDD MongoDB.
Info: En el primer caso el dataset creado es un "hijo" del original (su actualización se puede ligar a la del "padre") excepto por los identificadores de los campo, los cuales es el usuario el que fija a voluntad a partir del nombre de los campos devueltos por la consulta. Si el usuario tiene cuidado de conservar los ids originales (en caso de que esto tenga sentido de acuerdo a la consulta programada) la relación padre-hijo es igual a la que se obtiene con la consulta general de Tabulae.
El "lenguaje" de programación es javascript.
El MapReduce de MongoDB consta de 4 bloques, dos obligatorios y dos opcionales.
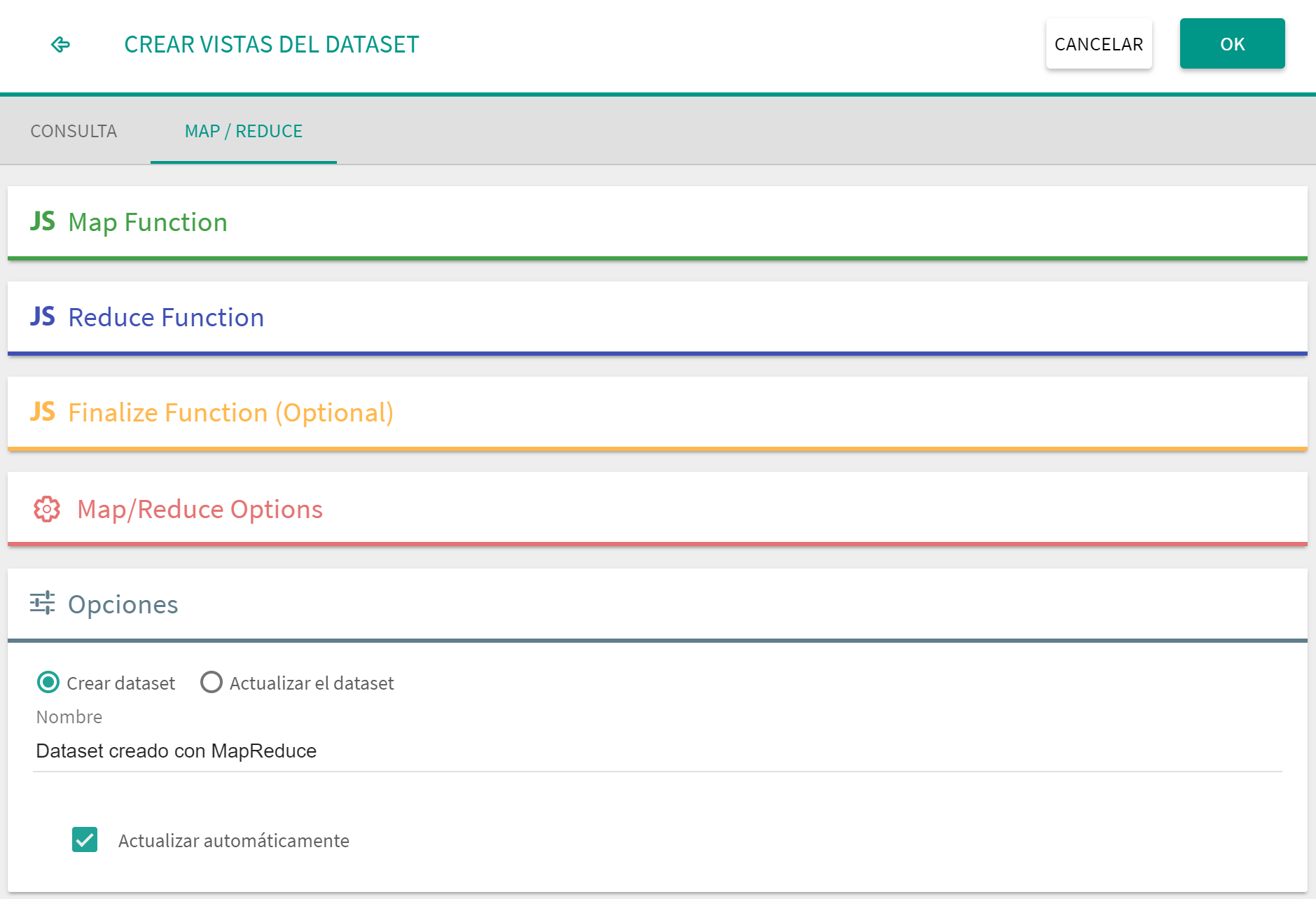
Descripción de los bloques MapReduce
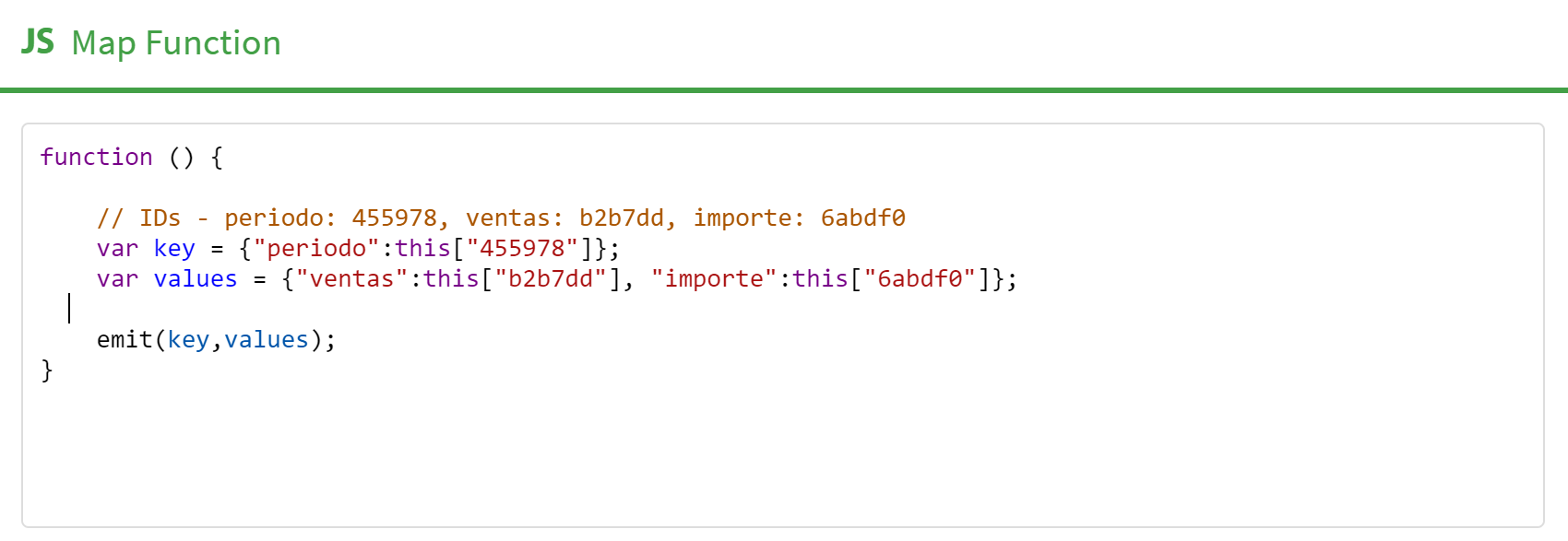
- Bloque función "Map": Este bloque obligatorio tiene estructura de función javascript, y será el que a partir de la información de entrada (filas del dataset) emite datos en forma de pareja atributo-valor
(key, value), ordenados por el objetokey. Tantokeycomovaluepueden de forma general ser objetos (documentos o arrays), aunque en su formato recuerde a una pareja de valores sencillos (atributo texto, valor numérico).
- Bloque función "Reduce": Este bloque obligatorio tiene estructura de función javascript, y será el que procede a reducir o agregar los registros con la operación deseada: para cada valor diferente de la
keyse devuelve un objetoreducedValue, siendo por tanto la salida los pares de valores(key, reducedValue). Es de hecho equivalente a hacer un agrupado por los valores de lakey, pero permitiendo programar la función de agregado que se desea.
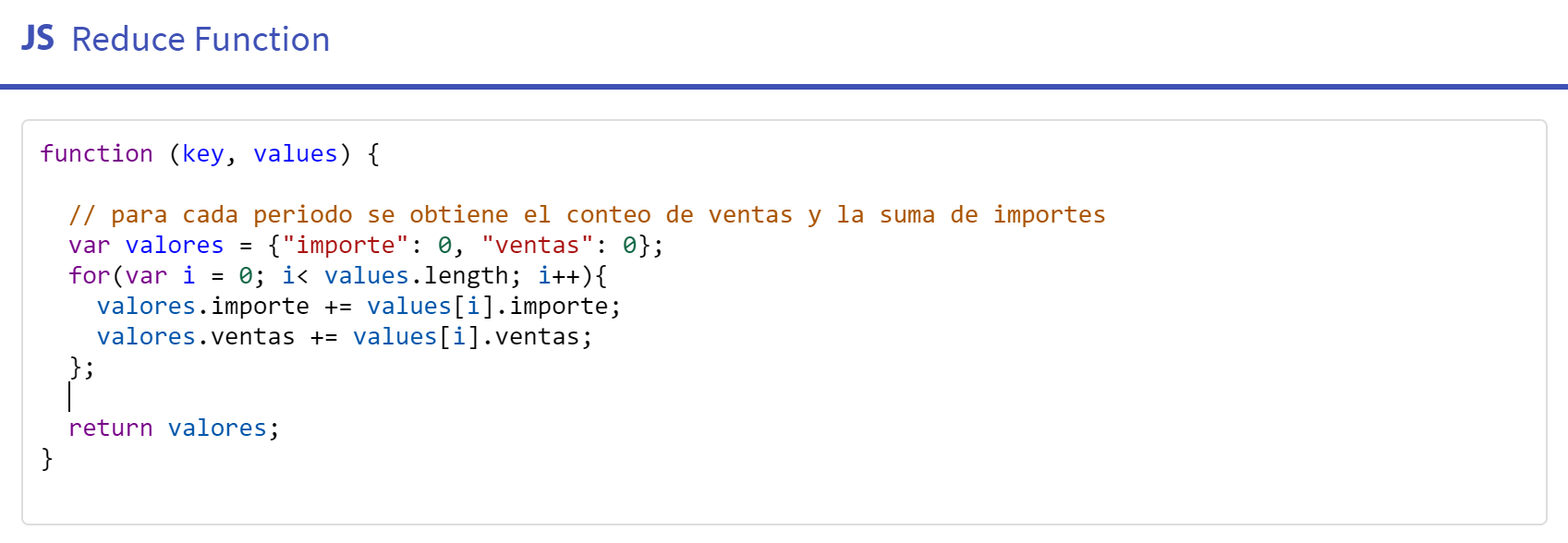
- Bloque función "Finalize": Este bloque no obligatorio permite realizar procesamientos posteriores al Reduce. Recorre las parejas
(key, reducedValue)que salieron del bloque Reduce y permite realizar operaciones, como por ejemplo operaciones "globales" (i.e., sobre todos los datos) si se usa la opción "scope", definida en el siguiente bloque.

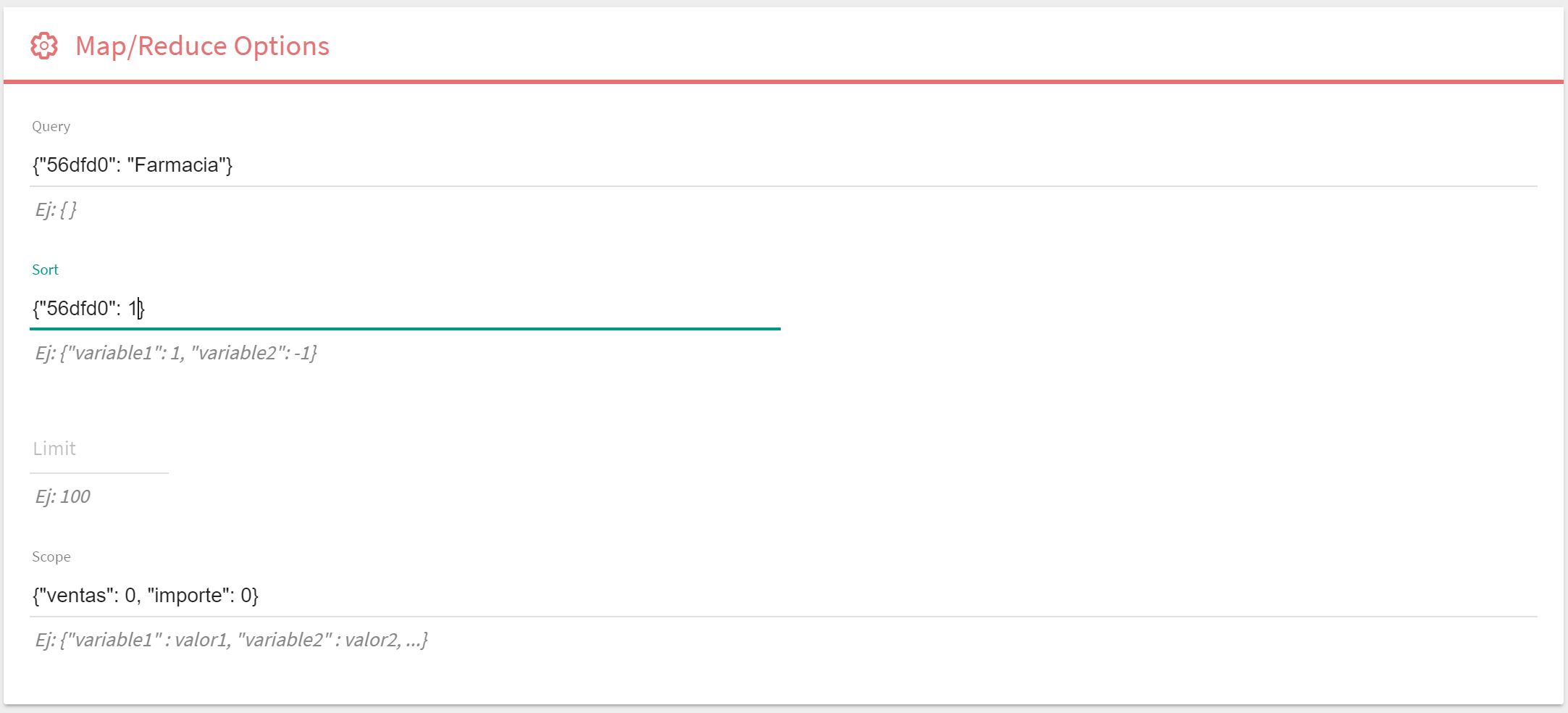
Bloque de Opciones: Este bloque no obligatorio permite incluir algunas opciones de control sobre la consulta:
Query: Permite definir un filtro sobre los datos de entrada.
Sort: Define un orden de entrada de los datos diferente al original.
Limit: Limita explicitamente el número de registros de entrada.
Scope: Permite definir variables globales (que se pueden usar en el bloque Finalize).